android学习笔记(1) 布局文件
RelativeLayout常用属性总结:
1. 属性值为true或false
Ø android:layout_centerHrizontal 水平居中
Ø android:layout_centerVertical 垂直居中
Ø android:layout_centerInparent 相对于父元素完全居中
Ø android:layout_alignParentBottom 贴紧父元素的下边缘
Ø android:layout_alignParentLeft 贴紧父元素的左边缘
Ø android:layout_alignParentRight 贴紧父元素的右边缘
Ø android:layout_alignParentTop 贴紧父元素的上边缘
2. 属性值必须为id的引用名“@id/id-name”
Ø android:layout_below 在某元素的下方
Ø android:layout_above 在某元素的的上方
Ø android:layout_toLeftOf 在某元素的左边
Ø android:layout_toRightOf 在某元素的右边
Ø android:layout_alignTop 本元素的上边缘和某元素的的上边缘对齐
Ø android:layout_alignLeft 本元素的左边缘和某元素的的左边缘对齐
Ø android:layout_alignBottom 本元素的下边缘和某元素的的下边缘对齐
Ø android:layout_alignRight 本元素的右边缘和某元素的的右边缘对齐
3. 属性值为具体的像素值,如30dip,40px
Ø android:layout_marginBottom 离某元素底边缘的距离
Ø android:layout_marginLeft 离某元素左边缘的距离
Ø android:layout_marginRight 离某元素右边缘的距离
Ø android:layout_marginTop 离某元素上边缘的距离
EditText常用属性总结:
Ø android:hint 设置EditText为空时输入框内的提示信息。
Ø android:gravity属性是对该view 内容的限定.比如一个button 上面的text. 你可以设置该text在view的靠左,靠右等位置.以button为例,android:gravity="right"则button上面的文字靠右
Ø android:layout_gravity是用来设置该view相对与起父view 的位置.比如一个button在linearlayout里,你想把该button放在靠左、靠右等位置就可以通过该属性设置.以button为例,android:layout_gravity="right"则button靠右
Ø android:layout_alignParentRight
Ø 使当前控件的右端和父控件的右端对齐。这里属性值只能为true或false,默认false。
Ø android:scaleType是控制图片如何resized/moved来匹对ImageView的size。
论文笔记——后缀数组
建议大家可以先去阅读两篇极品论文
1、IOI2004国家集训队论文——《后缀数组》(许智磊)
2、IOI2009 国家集训队论文——《后缀数组——处理字符串的有力工具》(罗穗骞)
一般理解这两篇论文之后并且能够实现倍增算法,那后缀数组也就应该可以算是打下基础了。我要说的只不过是自己的一些感悟和自己看得比较吃力的地方,希望对大家有所帮助。
关于一些定义以及性质(“//”注释符后面的为本人的笔记):
后缀数组 后缀数组SA是一个一维数组,它保存1..n的某个排列SA[1],SA[2],...SA[n],并且保证Suffix(SA[i])<Suffix(SA[i+1]),1≤i<n。也就是将S的n个后缀从小到大进行排序之后把排好序的后缀的开头位置顺次放入SA中。(1)
//这里对后面的k-后缀数组的定义起了决定性的作用。
名次数组 名次数组Rank=SA-1,也就是说若SA[i]=j,则Rank[j]=i,不难看出Rank[i]保存的是Suffix(i)在所有后缀中从小到大排列的“名次”。(2)
//名次数组也在一定程度上结识了后缀数组的“成分”。
k-后缀数组SAk保存1..n的某个排列SAk[1],SAk[2],…SAk[n]使得Suffix(SAk[i]) ≤kSuffix(SAk[i+1]),1≤i<n。也就是说对所有的后缀在k-前缀比较关系下从小到大排序,并且把排序后的后缀的开头位置顺次放入数组SAk中。
//也就是该后缀的长度为k。结合(1)
k-名次数组Rankk,Rankk[i]代表Suffix(i)在k-前缀关系下从小到大的“名次”,也就是1加上满足Suffix(j)<kSuffix(i)的j的个数。通过SAk很容易在O(n)的时间内求出Rankk。
//同上。
倍增算法(Doubling Algorithm),它正是充分利用了各个后缀之间的联系,将构造后缀数组的最坏时间复杂度成功降至O(nlogn)。
对一个字符串u,我们定义u的k-前缀
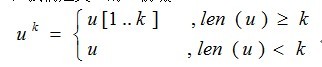
定义k-前缀比较关系<k、=k和≤k:
设两个字符串u和v,
u<kv 当且仅当 uk<vk
u=kv 当且仅当 uk=vk
u≤kv 当且仅当 uk≤vk
直观地看这些加了一个下标k的比较符号的意义就是对两个字符串的前k个字符进行字典序比较,特别的一点就是在作大于和小于的比较时如果某个字符串的长度不到k也没有关系,只要能够在k个字符比较结束之前得到第一个字符串大于或者小于第二个字符串就可以了。
根据前缀比较符的性质我们可以得到以下的非常重要的性质:
性质1.1 对k≥n,Suffix(i)<kSuffix(j) 等价于 Suffix(i)<Suffix(j)。
性质1.2 Suffix(i)=2kSuffix(j)等价于
Suffix(i)=kSuffix(j) 且Suffix(i+k)=kSuffix(j+k)。
//要使2k长的后缀相等,可以理解为分别从i、j开始的长度为k的后缀相等,且分别从i+k、j+k开始的长度为k的后缀相等。反之,依然。
性质1.3 Suffix(i)<2kSuffix(j) 等价于
Suffix(i)<kSuffix(j) 或 (Suffix(i)=kSuffix(j) 且Suffix(i+k)<kSuffix(j+k))。
//原理同上。
这里有一个问题,当i+k>n或者j+k>n的时候Suffix(i+k)或Suffix(j+k)是无明确定义的表达式,但实际上不需要考虑这个问题,因为此时Suffix(i)或者Suffix(j)的长度不超过k,也就是说它们的k-前缀以'$'结尾,于是k-前缀比较的结果不可能相等,也就是说前k个字符已经能够比出大小,后面的表达式自然可以忽略,这也就看出我们规定S以'$'结尾的特殊用处了。
//这一段可以说是倍增思想的源头,为什么可以用倍增思想?怎样将倍增思想用在后缀数组的构造上?
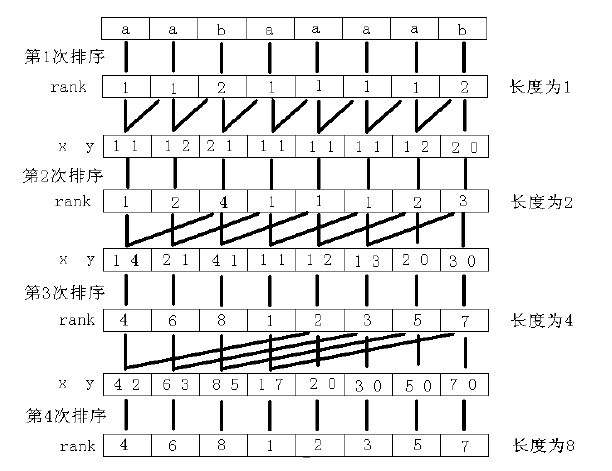
//看了罗同学的这张图,应该就可以理解倍增算法在构造后缀数组时起得作用了吧。
假设我们已经求出了SAk和Rankk,那么我们可以很方便地求出SA2k和Rank2k,因为根据性质1.2和1.3,2k-前缀比较关系可以由常数个k-前缀比较关系组合起来等价地表达,而Rankk数组实际上给出了在常数时间内进行<k和=k比较的方法,即:
Suffix(i)<kSuffix(j) 当且仅当 Rankk[i]<Rankk[j]
Suffix(i)=kSuffix(j) 当且仅当 Rankk[i]=Rankk[j]
因此,比较Suffix(i)和Suffix(j)在k-前缀比较关系下的大小可以在常数时间内完成,于是对所有的后缀在≤k关系下进行排序也就和一般的排序没有什么区别了,它实际上就相当于每个Suffix(i)有一个主关键字Rankk[i]和一个次关键字Rankk[i+k]。如果采用快速排序之类O(nlogn)的排序,那么从SAk和Rankk构造出SA2k的复杂度就是O(nlogn)。更聪明的方法是采用基数排序,复杂度为O(n)。
求出SA2k之后就可以在O(n)的时间内根据SA2k构造出Rank2k。因此,从SAk和Rankk推出SA2k和Rank2k可以在O(n)时间内完成。
下面只有一个问题需要解决:如何构造出SA1和Rank1。这个问题非常简单:因为<1,=1和≤1这些运算符实际上就是对字符串的第一个字符进行比较,所以只要把每个后缀按照它的第一个字符进行排序就可以求出SA1,不妨就采用快速排序,复杂度为O(nlogn)。
于是,可以在O(nlogn)的时间内求出SA1和Rank1。
//HDU 1403 Longest Common Substring中关于SA1和Rank1的构造
//花O(n)的时间对h=1进行基数排序
for(i=0;i<L;i++)
B[szText[i]]++;
for(i=1;i<256;i++)
B[i]+=B[i-1];
for(i=L-1;i>=0;i--)
Suffix[--B[szText[i]]]=i;
//计算Rank(1),因为仅仅是1阶的Rank,所以有并列的
for(Rank[Suffix[0]]=0,i=1;i<L;i++)
{
if(szText[Suffix[i]]==szText[Suffix[i-1]])
Rank[Suffix[i]]=Rank[Suffix[i-1]];
else
Rank[Suffix[i]]=Rank[Suffix[i-1]]+1;
}
//Suffix数组即为SA1,Rank即为Rank1。
求出了SA1和Rank1,我们可以在O(n)的时间内求出SA2和Rank2,同样,我们可以再用O(n)的时间求出SA4和Rank4,这样,我们依次求出:
SA2和Rank2,SA4和Rank4,SA8和Rank8,……直到SAm和Rankm,其中m=2k且m≥n。而根据性质1.1,SAm和SA是等价的。这样一共需要进行logn次O(n)的过程,因此可以在O(nlogn)的时间内计算出后缀数组SA和名次数组Rank。
Say something and to remember what I should do.
我也不知道为何最近看什么都是不顺眼,就连自己喜欢的菜我都食之无味了。在前进的路上缺少一起奋斗的人着实让人难受,如果我在HDU,或者MB在WZU,我想我也不会这样迷茫了。当初是他给了我新生,是他带给我ACM,让我知道我还有事情可以奋斗。然后在诚如上一篇日志所述,开始自以为很充实的AC之旅。直到半路chevy和MB的先后离开,或许这种竞赛在中国确实会变得面目全非,或许也不是每一个人都适合做着一件事,就像MB说的,不经过OI的熏陶直接做ACM那难度是可想而知的,并不是每个人都能像HDU的HH牛一样。不过财哥当初在我犹豫时,说了这样一句话“我们做竞赛只是为了能多学一点东西,能拿奖最好,不拿也无所谓,毕竟大家的起点不在一起。”也正是这一番话让我坚持到现在。但愿它能陪我走下去。是啊,人生不就是在学习吗?
最近终于跨入了HDU's Ranklist Top 100。不过也只是水题和模板题的积累罢了,我毫无底气,因为我也不知道有多少是自己真正记住并能熟练运用的。9月各大regional就要上线了,时间也是紧迫,作为第一次参赛的我来说,enjoy it!能进现场赛最好咯!Come On!
从A+B到线段树以及离散化操作
记得是去年的12月份,在HDU上开始了各大OJ的切题。一开始所到之处就是A+B。然后很认真的以为HDU的OJ是按难度来编排题号的,所以也就认真的从1000做下去了。没做多少题就发现难度很大,对于一个刚学会语言的控制结构的初学者来说,没有强大的抽象思维能力,很难顺切。然后就是开始了各种搜书活动。从《The C Programming Language》、《C Primer Plus》、《C++ Primer》到《Introduction to Algorithm》、《Data Structures》、《Thinking in C++》,短短半个月,败掉了好多金,不过我个人更倾向于“投资”这种说法。眼看大半年过去了,C++的面向对象技术依然一知半解,几本书同时推进的确压力很大,特别是《Introduction to Algorithm》,没有OI功底的我看着就如天书一般,唯一值得庆幸的是我还在坚持,也陆续完结了一些书本的学习。不过很多书籍还是要多多回顾和联系。
最近的集训最大的感触还是弱校的ACM环境确实不好,有人游戏有人看片,专题准备的好坏也就不予评价,但是至少我们既然选择做了,就要好好准备。想想我花了1个月去攻克八数码,仅仅是想让我们都少走弯路,暑期回家的那20天,切了ZJU和HDU大部分的search,也就是为了呈现给队友们更好的专题。但是我很失望,队列是什么居然还要我花半个小时去解释,状态压缩过程中的位操作还要我在黑板演示,什么hash也都不知道。我本来打算讲解如何去分析search以及search中的细节的运用,却演变成了基础课一般。更夸张的是,几天下来,很多东西主讲人都更在乎的是如何将题目转化到模板,很少去关注这个算法是如何产生的。也就好比高中有些科目,老师只叫我们如何解题,告诉我们记住就好,却不告诉我们为何这么解。很多人大概是抱着混日子的想法来集训的吧,居然还有人准备Big Number,我真想冲上去说一句Big Numer用Java可以瞬秒!Math Theory这一讲居然讲素数,讲欧几里德,讲中国剩余定理。好吧,你讲就讲吧,里面的定理居然不给我证明,真是扯淡啊!有人会说我们才大一,但是怎么不想想几天后我们就是大二的人了。不过有几个人的专题也着实让我喜欢,胡bw的几何,lkj的DP都让我感受颇深。bw的几何带给我的不仅仅局限于几何,而且深入了离散化操作以及线段树的操作,的确让我很惊喜。
贴一个代码,也算是这几天来最有成就感的事情,倘若不是bw的讲解,或许我至今都不知道这就是离散化操作。
/*
这段程序的效率不是很高,不过容易理解
它的主要原理是,把 Y 轴离散化(以所有矩形的Y轴坐标为间断点)
把线段放进线段树中,记录纵线,按X轴排序,(最后会沿X轴正方向把面积一层一层地加起来 )
用cover记录线段被矩形覆盖的次数,当然被覆盖两次以上的就符合条件了
然后用crossLen记录在该横坐标,对应的纵坐标上有多少长度被覆盖两次(这里就用到线段树了)
然后乘上离下个坐标的距离,就得到了该层的面积;最后把每层的加起来就是答案。
*/
#include<stdio.h>
double y[5000];
struct TREE
{
double left,right,len,crossLen;
struct TREE *leftSon,*rightSon;
int cover;
}tree[5000],*Root;
struct line
{
double x,y1,y2;
int cover;
}point[5000],Temp;//用于记录纵行
int idx; //用于树的生长
struct TREE *CreatKid()
{
struct TREE *p;
p=&tree[idx++];
p->cover=0;
p->len=p->crossLen=0;
p->leftSon=NULL;
p->rightSon=NULL;
return p;
}//为root找一个tree里的空间,并初始化
struct TREE *CreatTree(int left,int right)
{
struct TREE *root=CreatKid();
root->left=y[left];
root->right=y[right];
if(right-left>1)//直到两个值在数组中相邻
{
int mid=(left+right)>>1;
root->leftSon=CreatTree(left,mid);
root->rightSon=CreatTree(mid,right);
}
return root;
}
void GetLen(struct TREE*root)
{
root->len=0;//len表示覆盖长度
if(root->cover>0)
root->len=root->right-root->left;
else if(root->leftSon!=NULL)
root->len=root->leftSon->len+root->rightSon->len;
}
//crossLen记录被覆盖两次以上的纵向长度
void GetCrossLen(struct TREE *root)
{
root->crossLen=0;
if(root->cover>1)
root->crossLen=root->right-root->left;
else if(root->leftSon!=NULL)
{
if(root->cover==1)
root->crossLen=root->leftSon->len+root->rightSon->len;
else
root->crossLen=root->leftSon->crossLen+root->rightSon->crossLen;
}
}
//需要注意的是,cover进入这个程序后就不可能小于零
void UpdateLen(struct TREE*root)
{
GetLen(root);
GetCrossLen(root);
}
//更新操作,程序的主要部分,是个递归函数,汇集子孙们更新后的数据给头
void Update(struct TREE*root,struct line t)
{
if(root->left==t.y1&&root->right==t.y2)
{
root->cover+=t.cover;
UpdateLen(root);
return;
}
if(t.y1>=root->leftSon->right)
Update(root->rightSon,t);
else if(t.y2<=root->rightSon->left)
Update(root->leftSon,t);
else
{
struct line tmp=t;
tmp.y2=root->leftSon->right;
Update(root->leftSon,tmp);
tmp=t;
tmp.y1=root->rightSon->left;
Update(root->rightSon,tmp);
}
UpdateLen(root);
}
int main()
{
int N,cas,i,j,u,k;
double x1,x2,y1,y2,ans,temp;
scanf("%d",&cas);
while(cas--)
{
scanf("%d",&N);
idx=j=0;
ans=0;//用来记录最后的面积
for(i=0;i<N;i++,j+=2)
{
scanf("%lf%lf%lf%lf",&x1,&y1,&x2,&y2);
point[j].x=x1;
point[j+1].x=x2;
point[j+1].y1=point[j].y1=y1;
point[j+1].y2=point[j].y2=y2;
point[j].cover=1;
point[j+1].cover=-1;
y[j]=y1;
y[j+1]=y2;
}
//对Y进行排序,为纵行离散化做准备,用于创建树
for(k=0;k<j;k++)
{
for(u=k;u<j;u++)
{
if(y[k]>y[u])
{
temp=y[k];
y[k]=y[u];
y[u]=temp;
}
}
}
//对point按X进行排序 ,就是对纵行进行排序
for(k=0;k<j;k++)
{
for(u=k;u<j;u++)
{
if(point[k].x>point[u].x)
{
Temp=point[k];
point[k]=point[u];
point[u]=Temp;
}
}
}
Root=CreatTree(0,j-1);//创建了线段树,并带回了树的头
Update(Root,point[0]);//更新操作
for(i=1;i<j;i++)
{
ans+=Root->crossLen*(point[i].x-point[i-1].x);
Update(Root,point[i]);
}
printf("%.2lf\n",ans);
}
return 0;
}